

when you acquire a set of numbers you would want to examine the data to find out distribution, maxium and minimum values outliers etc. This is an important part of data analysis, since it helps you to know if you data meet assumptions required by other analyses such as t-test. For this example, we’ll look at the given below table.

In Excel, select Tools/Data Analysis/Descriptive Statistics. (If the Data Analysis option is not on your Tools menu, you must first install it using Tools/Add ins…).
- Run Microsoft Office Setup to add components to MS Office
- Select Analysis Toolpak under the Excel group of software items.
Once this is done
- Run Excel
- Select Addins in the tool menu. ( In EXCEL 2007 Add-ins tab is in the excel option dialogue box)
- In the dialogue box select Analysis Toolpak and then click on the OK button.
Now you have an extra command, Data analysis on the Tools Menu and you can do the statistics.
Select the input range. In this case it is $A$1:$A$10.

Be sure to select the check boxes Summary Statistics and Confidence level for mean (95% is okay). The output created is shown here:
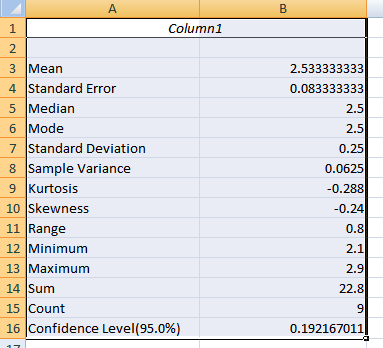
Information you should notice includes:
Symmetry:
The Skewness measure indicates the level of non-symmetry. If the distribution of the data are symmetric then skewness will be close to 0 (zero). The further from 0, the more skewed the data. A negative value indicates a skew to the left. How do you tell if the skewness is large enough to case concern. Excel doesn’t give you this value, but a measure of the standard error of skewness can be calculated as =SQRT(6/N) or =SQRT(6/9 which is 0.816. If the skewness is more than twice this amount, then it indicates that the distribution of the data is non-symmetric. In this case 0.816 * 2 = 1.69. The skewness reported by Excel is -0.214 so the data can be assumed to be fairly symmetric. However, this does NOT indicate that the data are normally distributed.
Kurtosis is a measure of the peakedness of the data. Again, for normally distributed data the kurtosis is 0 (zero). As with skewness, if the value of kurtosis is too big or too small, there is concern about the normality of the distribution. In this case, a rough formula for the standard error for kurtosis is =SQRT(24/N) = 1.63 .Twice this amount is 3.2. Since the value of kurtosis falls within two standard errors (-0.28) the data may be considered to meet the criteria for normality by this measure. These measures of skewness and kurtosis are one method of examining the distribution of the data. However, they are not definitive in concluding normality.
Estimate of central tendency:
For normally distributed data the mean (arithmetic average) is the typical value to use in a report. The median is another measure of central tendency and is usually reported when the data are not normally distributed. The mode, or the most frequent value, is a third measure of central tendency.
Measures of variability:
The measures of variability reported in Excel’s descriptive statistics include the standard error, the standard deviation and the variance as well as the range. The first three measures are related in the following ways:
Standard Deviation = SQRT(Variance)
Standard Error = Standard Deviation / SQRT(N)
Coefficient of Variation:
Another measure often reported is the coefficient of variation. This measure provides a unitless measure of the variation of the sate by translating it into a percentage of the mean value. This measure not provided by Excel, but is easily calculated by the formula:
CV = (Standard Deviation / Mean) * 100
>>Continue reading: ANOVA with Excel, t-test with excel
0 comments:
Post a Comment